AngularJS单页面的SEO静态化的策略与实现
2020年03月24日
随着互联网的飞速发展,使用传统静态页面和JavaScript技术开发一个大型网站的难度越来越高。而Google推出的AngularJS则是基于传统JavaScript的一个MVC框架,开发者可以通过它来编写目前主流的单页面应用。它克服了HTML在构建大型Web应用上的不,使用HTML作为模板,简化应用组件,利用依赖注入和数据绑定,使开发人员可以更有效地进行一些大型网站以及APP的开发。为了使AngularJS开发的页面支持搜索引擎爬虫,需要对此单页面模式进行搜索引擎优化(SEO)。
现有对于AngularJS单页面的SEO策略的研究和相关文献较少,所以本文还结合了相关社区、论坛等一系列的网络资源。本研究对AngularJS单页面的动态数据无法被爬虫解析到的问题提出了非实时和实时静态化的两种基于JavaEE拦截器的SEO策略。
1单页面静态化策略
1.1策略一:非实时的静态化
智能识别爬虫机器人返回定期更新的缓存页面的非实时静态化SEO原理如图1所示。具体分为:①在项目部署或者在设定的一段时间后,对页面进行后台的获取、遍历,通过配置文件设定的遍历深度开始对首页进行深度的链接获取以及转义,将各个链接对应的页面交给下一步处理,直到所有遍历结束;②对遍历的页面进行SEO处理,生成或更新静态HTML缓存放入静态页面池,即配置文件设置的缓存路径,并在遍历结束后及时对无效链接的缓存进行清理;③网络请求首先通过拦截器(SEOFilter),拦截器根据HTTP请求的请求头中包含的“User-Agent”等参数判断此请求是否为爬虫机器人的请求,如果不是则返回正常的页面用于AngularJS内部渲染显示,反之则通过URL转义查询并返回对应的SEO缓存页面给爬虫机器人用于抓取关键字。
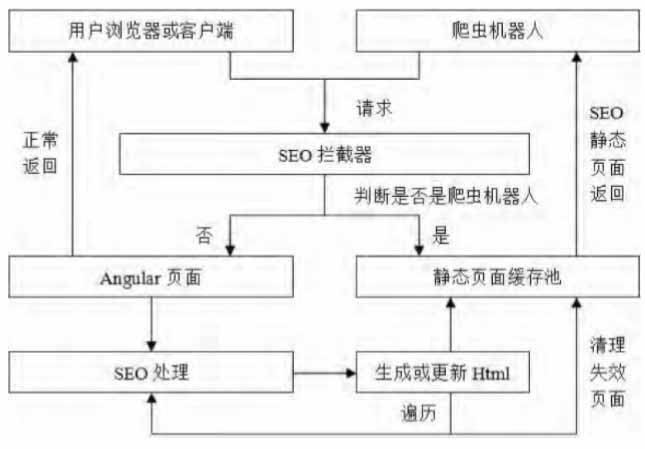
图1非实时的静态化SEO原理图
由于此策略是非实时的,所以它适用于较为稳定且对于搜索引擎的实时性要求不高的网站。例如政府办公网站,它每日更新的内容不多且不会频繁地修改页面内容,则可以每日对服务器的静态页面进行更新,即可满足每日更新搜索引擎词条的需求。
1.2策略二:实时的静态化
策略一为非实时的静态化策略,然而它不会很好地适用于需要经常更新数据且对搜索引擎实时性要求较高的大型门户网站。例如大型的新闻网站,网站经常会发布新的文章或者是公告,并且需要搜索引擎能够尽快地将新闻的链接和关键词加入索引,那么频繁更新缓存页面的服务器开销会很大,并且缓存文件所占的空间也会越来越大,因此针对此种情况提出了实时的静态化策略。请求页面时即时生成定时销毁的静态页面缓存,爬虫机器人请求时,首先查找是否存在缓存以及页面缓存是否失效,如果缓存有效则返回静态池中的静态页面,反之则生成新的静态页面或者更新静态池内的静态页面,修改后的实时静态化策略原理如图2所示。
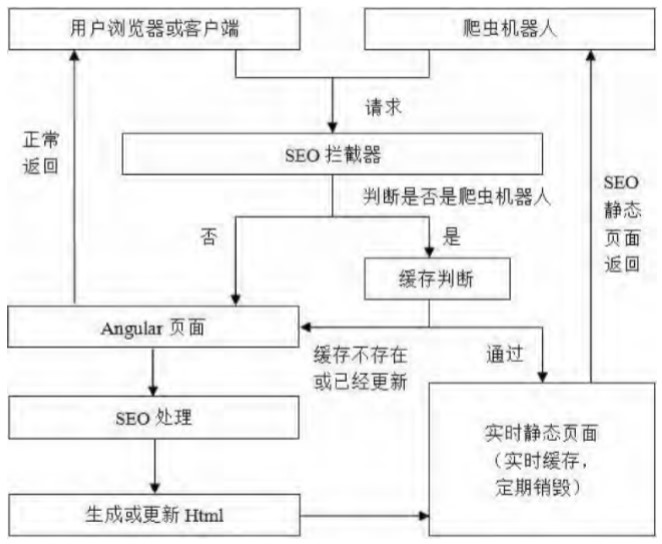
图2实时的静态化SEO原理图
同时,此实时静态化策略也改进了页面的缓存方式,它对于不同缓存页面的关键字设置不同的清理权重(即更新频率高低,需要人工设置)。较为稳定的页面——例如首页菜单、公司信息等展示页面可以设定较小的权重值;更新比较频繁的页面,例如新闻公告、发布消息的汇总页则可以设定较大的权重值。权重越小的静态页面的缓存时间越久,可以保存一天甚至是一周,这样可以大幅节省频繁生成此类缓存的资源浪费;而权重越大的静态页面由于更新频繁,所以缓存时间越短,考虑到搜索引擎的爬虫机器人不会实时抓取信息,而是间隔一段时间(一般为四至五小时)才会重新抓取,因此可以在两到三小时或更短的时间后清理此类缓存。这里的缓存也可能会清理失败,所以在判断缓存是否存在的同时也需要检查静态页面的失效时间,避免过时的旧页面缓存影响新发布信息的检索。策略还规定了当网站重新部署后强制清理所有缓存。
2单页面静态化策略实现及测试
2.1实现步骤
静态化策略的实现主要分成配置拦截器以及拦截器实现两步。首先将AngularJS的Web项目加入JavaEE的webapp文件夹中,设置WEB-INF/web.xml文件,确定外部工具路径、缓存路径、遍历深度、拦截规则等参数,下面为少量配置代码:
<web-app>
<filter>......
<init-param>
<param-name>crawlDepth</param-name>
<param-value>10</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>SEOFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
</web-app>
针对策略二的实时静态化SEO策略的拦截器SEOFilter的实现原理如图3所示。

图3实时静态化策略的拦截器SEOFilter工作原理图
拦截器首先判断请求的发送方,如果不是爬虫机器人则直接返回正常的页面,反之则返回SEO实时静态化页面。针对爬虫机器人的处理流程主要为:首先进行URL转义,爬虫请求分析,记录URL并查询遍历深度(没有此项参数则使用配置文件中的默认值);再将URL进行二次转义,查询缓存文件;如果存在缓存文件并且没有失效,则直接返回SEO静态页面;如果缓存文件不存在,或者缓存已失效并未及时销毁,则先销毁缓存,再进入SEO处理器;SEO处理器利用第三方工具PhantomJS,它是一个以WebKit为基础的服务器端JavaScript的API,不依赖于浏览器,全面支持各种Web标准,例如页面文档对象模型(DocumentObjectModel,DOM)处理等———对动态页面进行搜索引擎优化;最后生成缓存页面,保存文件至缓存文件目录(缓存池),返回SEO静态页面。
2.2测试与分析
测试环境的系统为WindowsServer2008R2,部署平台为Tomcat7.0.70,端口8083为实时静态化策略实现后的网站访问入口,端口8084则为原始的AngularJS网站的访问入口。
首先使用浏览器访问网站,拦截器判断出请求为浏览器请求,并在控制台显示浏览器版本,浏览器可以正常浏览网页;之后再使用模拟百度爬虫机器人的工具分别对原始网页和策略实现后网页进行爬虫,并显示抓取的页面信息。图4表明了爬虫机器人只能抓取AngularJS单页面中的部分关键字,包括标题、页面底部描述等信息;而使用实时静态化策略后,如图5所示,拦截器识别出了爬虫机器人然后在控制台显示,同时返回了SEO静态页面,并且图6表明了网页中的动态数据已经可以被一般的爬虫机器人抓取到,并显示有用的关键字,包括发布公告、网站信息等主要标题与信息。
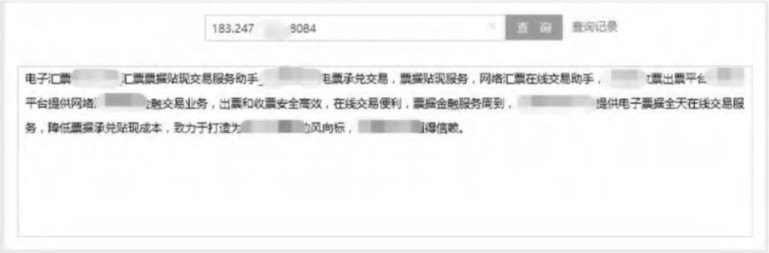
图4模拟百度爬虫机器人抓取原版首页的结果图
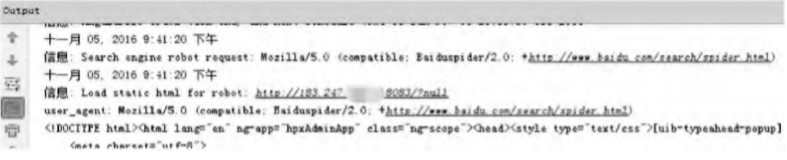
图5模拟百度爬虫机器人抓取策略实现后首页的控制台信息图

图6模拟百度爬虫机器人抓取策略实现后首页的结果图
3结束语
本文提出了非实时和实时静态化的两种SEO策略,它们均可以实现AngularJS单页面SEO静态化的预期目的,不过它们也存在着一些不足。策略一针对的是较为稳定且对搜索引擎检索实时性要求不高的大型网站,例如政府办公网站等。它可以定期对网站中的静态页面进行更新,但是对于实时性要求较高的门户网站,它会频繁地重新遍历所有静态页面,大大增加服务器的压力,生成所有缓存的时间和服务器缓存页面的数量也会相应增加。策略二针对的则是对搜索引擎检索实时性要求较高的大型门户网站,例如新闻网站等。它尽可能增加缓存页面的实时性并且节约缓存文件的空间,但是对于实时性要求不高的网站,它会频繁地销毁再生成不需要实时更新的页面缓存,这也会浪费服务器的部分资源。因此,需要根据当前网站对于搜索引擎检索实时性的要求来选择适合的策略。同时,本文的重点在于对AngularJS单页面的SEO静态化的策略与实现,所以对于关键字的优化还可以做进一步的研究。最后,搜索引擎优化是对于整个系统的一个协同优化的过程,它由内部设计因素和外部链接因素共同影响,SEO其实只是一个辅助行为,对于一个网站更重要的是其内容的全面与创新。
上一篇:如何把SEO搜索引擎优化引入XHTML+CSS网页设计中
下一篇:响应式网站的优势和核心技术及设计方法
